Indexing with staging propagation
When indexing with staging propagation, business users apply changes to a staging area, which is later propagated into the production environment by IT administrators. An index repeater is used to capture the most recent deployed index content, while also serving as a backup.
In an event of applying an emergency change, the repeater can be used for reindexing instead of directly against the search index cluster that is in production. This can avoid any potential downtime due to corruption during reindexing. That is, the search index cluster that is in production is always treated as subordinate servers, with the reindexing always against the repeater. After the reindexing successfully completes, the delta changes are replicated into the subordinate nodes in the search cluster that is in production. This index replication seems seamless to administrators, since after the replication completes in the production system, the new version of the search index automatically becomes live.
Search index flow with staging propagation and the workspace index
Timeline of events
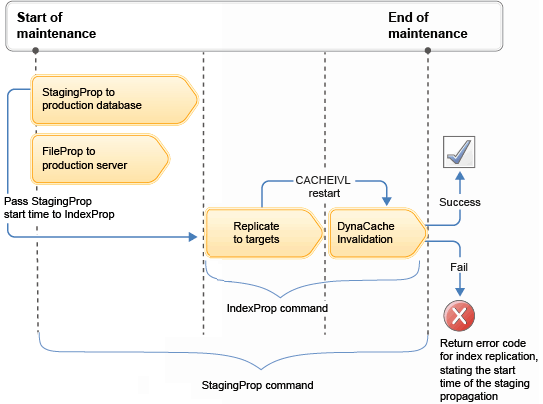
Where:
- A start time is passed as a parameter to the indexprop utility at the time the command is issued by an IT Administrator.
- This start time defines the period where cache invalidation starts. Typically, the start of the staging propagation operation.
- The indexprop utility monitors the progress of the index replication on all the search subordinate servers in production.
- After all of the index replications are completed successfully, the indexprop utility issues a cache invalidation instruction by inserting an entry of type restart into the CACHEIVL table, by using the provided start time parameter as the time to start performing cache invalidation.
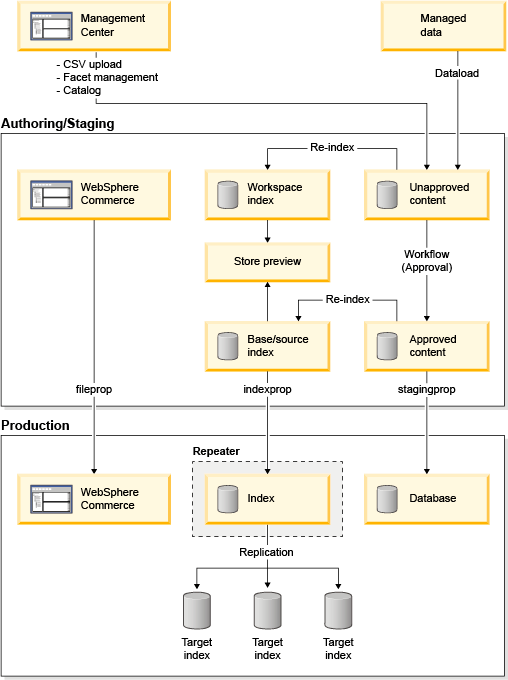
- Catalog changes are made in WebSphere Commerce with the Management Center or Data Load utility in a staging environment. Business users test and preview all the changes in this preproduction environment before the changes are published into the production servers. In this scenario, there is a dedicated search index for the staging environment and the delta update procedure for synchronizing the catalog changes is the same as in a non-staging environment.
- The workspace search index is used for business users to preview changes that are made in the Management Center, for example, uploading CSV files or other catalog changes.
- When business users are satisfied with their changes, the data is released and published into
production by using staging propagation (stagingprop). The utility is used by IT administrators to
coordinate the following tasks when publishing into production:
- fileprop
- Used for attachments and other assets such as JSP files and HTML files.
- stagingprop
- Used for managed data such as catalog and configuration.
- The indexprop utility is used
to propagate the WebSphere Commerce Search index:
- The indexprop utility is used by IT administrators to initiate the search index replication from the staging server to the repeater, and perform cache invalidation for WebSphere Commerce Search in production. For more information, see Propagating the WebSphere Commerce Search index with the repeater.
For more information on how to update the replication configuration file (replication.csv), download and extract the following archive that contains sample CSV files sdsearch_replication_samples.zip.Note: When running the UpdateSearchIndex scheduler job:- The UpdateSearchIndex scheduler job does not run indexprop by default. Therefore, the replication.csv does not need to be copied to a location outside the Solr home directory.
- The replication.csv file should be copied to a location outside the Solr home directory. This avoids replication automatically taking place every time the UpdateSearchIndex scheduler job is run. For example, copy the replication.csv to the WC_installdir/instances/instance_name/search directory. Then, pass the -solrHome value when running the indexprop command.
- The search index repeater is used as both a master
and a subordinate for search replication.
It is used as a subordinate when replicating with the staging search index, where the staging search index is the master and the repeater is the subordinate acting as a backup of the search index for production. After the first replication is completed from staging, the repeater communicates the changes to its subordinate nodes that are in production.
The repeater then becomes the master, where all nodes from the search index cluster are configured to poll changes from the repeater on a regular preconfigured fixed-time interval. This time interval is defined in the solrconfig.xml file under
replication.Replicating between the repeater and all search index clusters in production can be automated, as the indexed data in the repeater always matches the indexed data in production. The search index repeater must be a subordinate to the staging search server and master to the production search server.
Important: The repeater must reside in Production, as it relies on the production database to perform emergency updates. - The following considerations must be noted when both catalog data and asset files are published
to production:
- The next time replication occurs between the production search index and the repeater.
- The approximate amount of time that the index replication might take to complete.
- Cache invalidation for the storefront must be performed before the updated changes are visible
in production.
- An automated cache invalidation can be performed by using the indexprop
utility.
When using the indexprop restart time option to perform reinvalidation, after all of the index replications have completed successfully, the indexprop utility issues a cache invalidation instruction by inserting an entry of type restart into the CACHEIVL table, using the provided start time parameter as the time to start performing cache invalidation. This allows the DynaCacheInvalidation scheduler command to perform the same invalidation again, starting at the given start time parameter. This prevents early invalidation, resulting in recaching out-of-date content before the latest index changes become available. These invalidation entries in the CACHEIVL table might be dependency IDs used for JSP fragment cache invalidation or data object cache invalidation.
- An automated cache invalidation can be performed by using the indexprop
utility.