Indexing site content with WebSphere Commerce search
WebSphere Commerce contains unmanaged content
such as site content, that must be crawled using the site content
crawler. Unmanaged content intended for production must be published
separately, as it is not part of staging propagation. Once the static
content is copied to the correct location, a manual site content re-indexing
from the production system is required against the repeater.
Site content crawler
The site content crawler crawls HTML and other site files from WebSphere Commerce starter stores to help populate the site content search index.
The site content crawler captures the site content, caches it in a local directory, and puts the entries into the manifest.txt file. It then maps the physical locations to their corresponding URLs. The indexer uses the manifest file to retrieve the physical temporary file locations, creates the indexes, and once tokenized, associates the file URLs with the index record.
The following table highlights the site content
crawler workflow:
| Site content crawler action | Site content crawler workflow |
|---|---|
| Site content crawler launches | The site content crawler:
|
| Site content crawler creates directory structure | The site content crawler:
The following diagram depicts a high-level overview of the
site content crawler directory structure: 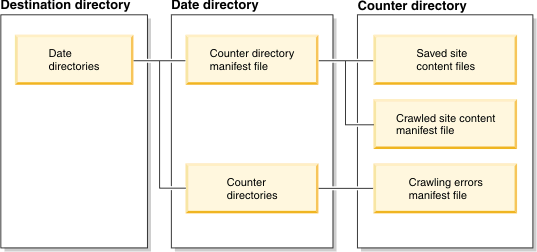 |
| Site content crawler crawls site content | The site content crawler:
|
| Site content crawler completes | If the site content crawler is successful, it:
|
Site content crawler and indexer integration
The
indexer acts as a service to the site content crawler. After each
crawl completes, the site content crawler directly invokes a request
to the WebSphere Commerce search server with the specific URL. The
indexing process then starts asynchronously. The typical URL resembles
the following sample URL:
- http://localhost/solr/unstructured_core_name/webdataimport?command=full-import&basePath=path_to_directory_of_manifest_file_with_path_separator_appended