Managing Always On Availability Groups
The content (automation plans, tasks, and scripts) for managing Windows 2008 R2 and later clusters can be used to provide enhanced monitoring and process improvement to manage Windows 2012 and later clusters with Always On Availability Groups (AAGs). To improve the performance by patching the appropriate node, include the monitoring tasks defined in this section in your automation plans.
Monitoring and patching process
Console Operators can plan patching Windows 2012 and later clusters with Always On Availability Groups (AAGs) in two phases. In the first phase, before a given maintenance window, they can monitor the nodes in the environment and manually patch secondary nodes. In the second phase, within the maintenance window, they can target the primary and standalone nodes. This helps to complete patching within the scheduled time limit without spill over, because only the active node is patched during the maintenance window.
Status Collector
Status Collector is a service implemented as a Windows scheduled task that collects important information about the cluster nodes. This task checks the status of the nodes to monitor the health of the failover cluster. This identifies which ones are primary and which ones are secondary nodes.
Prerequisites
Following are the prerequisites to install Status Collector.
- Operating System: The cluster nodes must have Windows® 2012 and later and must be configured with AAGs.
- Database: The database on the nodes must be MS SQL enterprise edition only.For detailed prerequisites, restrictions, and recommendations for Always On Availability Groups , see https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/prereqs-restrictions-recommendations-always-on-availability?view=sql-server-ver16
Status Collector Tasks
Status Collector runs on the cluster nodes. The scheduled task periodically executes a PowerShell script to query the node and reports the required information throughAnalysis 176 - Status of the
Always-On failover cluster.The following are the Tasks available to install, edit, and uninstall Status Collector.
- Task 173 - Deploy Status collector for Windows cluster
- Run this Task to install Status Collector. This task checks if the Windows Task
Scheduler service is enabled and set to Automatic. If yes, it creates a new task to
invoke the provided PowerShell script and the Trigger will be a schedule
reflecting the frequency chosen by the Console user. The PowerShell script gathers the
node status and writes this information together with the execution timestamp, in a file
to be saved in a fixed location (output file location will be <BES Client
folder>\Applications\StatusCollector folder).Important:You can configure the following settings while installing Status Collector.
- This Task becomes relevant only for the computers that have SQL Server service and Windows Cluster service installed. The applicability of the install Task checks for the Status Collector to be already scheduled in the Windows task Scheduler.
-
This is a specific scheduled task to support AAGs. If this task is deployed with another type of Windows cluster other tha AAGs, it does not report any information.
- As far as the scheduled task is configured, the user account used to run it is set as SYSTEM by default. If you want it to run under a different user account after the installation, ensure the user account has the required privileges to execute the PowerShell script. To configure the user account, open the Windows scheduled task, and under General→Security options, change it to the required value.
- Task 174 - Edit Status collector for windows cluster
- With this Task, you can modify the settings (Polling time for script execution, DB
Instance name, Threshold for Logs folder) configured during the installation of Status
Collector through
Task 173 - Deploy status collector. This Task reconfigures Status Collector on the fly without the need to uninstall or re-deploy it.
- Task 175 - Remove Status collector for windows cluster
- This Task uninstalls Status Collector that was previously installed. When you uninstall, you cannot monitor through Status Collector anymore.
Analysis to monitor the status
Analysis 176 - Status of the Always-On failover cluster. With this
analysis, user can monitor and configure the roles of the nodes such as Primary, Secondary,
or Standalone node. It reports the timestamp at which the active node last reported. Based
on this, the Console Operator can decide which node to be patched within and outside the
maintenance window and ensure high availability. This analysis displays the following
information.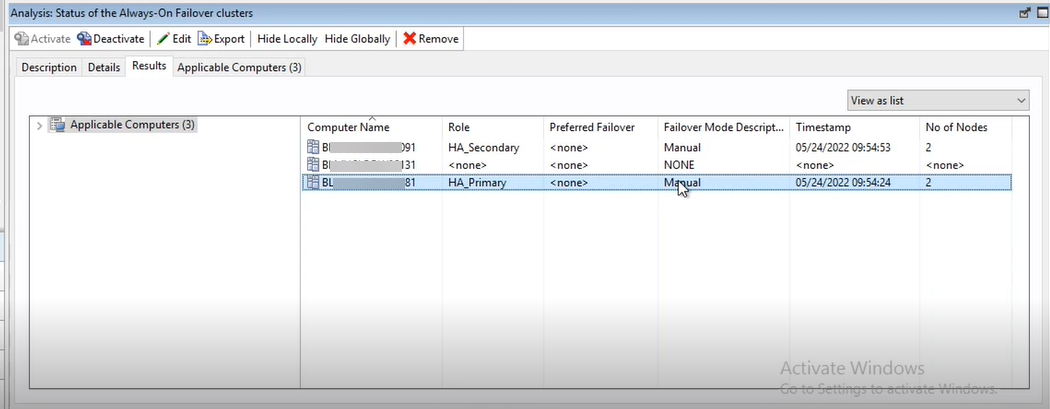
- Computer Name
- Computer name of the node in a cluster.
- Role
- Role of the node as configure by the user such as HA_Primary, HA_Secondary, and Standalone.
- Failover mode description
-
- Manual – If the HA_Primary node goes down, it does not switch over to secondary node automatically. User must manually select another node as HA_Primary.
- Automatic – If the HA_Primary node goes down, it automatically switches over to the secondary node configured under Preferred Failover column.
- None – When the node is not configured with AAG cluster, it displays <None>.
- Preferred failover
-
If Automatic failover mode is selected, when the HA_Primary node goes down, the server name mentioned under Preferred failover becomes the HA_Primary node.Important: Ensure the server mentioned under preferred failover is patched outside the maintenance window appropriately to enable it to respond immediately in case of failure of the primary node.
- Timestamp
-
Timestamp shows the date and time at which the data was collected from the nodes to display in the analysis. This indicates when the server responded to the query at the latest. Based on this timestamp, Console Operators can decide if the server status has changed. This can help to decide which server to patch within or outside the maintenance window.
- Number of nodes in the cluster
-
It shows the number of nodes configured in the cluster that a node belongs to.
Task 344 – Make node unavailable as possible owner of resources in cluster with safety check
This Task is an updated version (besides
the currently available version) of fixlet responsible for marking Cluster nodes
unavailable.
This Task is available only for the clusters with 3 or more nodes. It performs an additional safety check before marking any node unavailable for the cluster failover. If the safety check fails, it retries another two times (three attempts in total).
This Task ensures that at any point in time, there are more than half the number of nodes are available to respond to the requests. The actual patching can proceed only if the number of available nodes is greater than half the number of nodes in the cluster, allowing for the failover process, and prevents any data loss. For example, if there are 3 nodes in a cluster, then the maximum number of nodes that can be taken out for patching is 1. The number of nodes that can be available are 2 (3/2=1.5). This prevents any data loss.
In a 3-node cluster, standalone is a replica of the active cluster. Primary and standalone are considered to be active and they both are patched inside the maintenance window.Since the previously mentioned algorithm is not applicable for the 2-node
clusters (there can never be more than half the nodes available nodes for failover),
fixlet responsible for marking Cluster nodes unavailable must be
used.
Logs and troubleshooting
- Errors and debugging information about the Status Collector becomes available in the folder BES CLient/Applications/StatusCollector/Logs.
- One or more logs files are saved with the name format: StatusCollector.<date>.log. Every log file name contains the corresponding date.
- The log files provide all the messages related to the queries to the cluster node.
- Depending on the disk space configured for accumulating the logs through the install or edit tasks, the latest logs are kept and oldest logs are automatically deleted.
- To troubleshoot the Status Collector, the starting point is the timestamp in the analysis which does not refresh after the configured refresh period for a specific node. It could be caused by the Task Scheduler service not running properly (in this case the edit fixlet can be used to reconfigure it to start automatically) or by other reasons. If the edit fixlet does not solve the issue, the Status Collector log file of the node which is not updating needs to be manually checked to troubleshoot the problem.