Fundamental concepts
In this module you can find fundamental concepts and terminology of BigFix ServiceNow Data Flow solution.
Data Sources
Administrators provide credentials for each data source using the IntegrationServices CLI, with the – ProvideCredentials command and an optional DataSource Name argument.
BigFix Service Account Requirements
To facilitate the import of ServiceNow CMDB data into BigFix, a Master Operator account is required. Otherwise, the minimum account requirements to send BigFix endpoint data to ServiceNow are the following:
-
A non-master operator account with permissions against the in-scope computers.
-
Read access to the BigFix ServiceNow Data Flow site.
-
The Can use REST API setting set to Yes
-
The Can Create Actions setting set to No.
ServiceNow Service Account Requirements
The ServiceNow Administrator should have a service account that leverages basic authentication with read and write access to the CMDB tables.
Adapters
BigFix Adapter
ServiceNow Adapter
When initiated in the context of a Data Flow, the ServiceNow Adapter extracts data from the CMDB_CI_COMPUTER table in ServiceNow, parses the results, and persists the changes to a cache file on the disk.
As a Target Adapter, the ServiceNow Data Flow Adapter processes changes received from the Source Adapter, detects changes, and updates the CMDB_CI_COMPUTER table.
Data Flows
Machine correlation
In an ideal scenario, every computer contains an identifier that can uniquely identify the system in both the source and target data sources. For instance, if your organization guarantees that a device is always uniquely identified by the host name and that data was available in both systems, then simple key matching could be performed to associate the records between the systems.
However, the definition of a computer between data sources and organizations is often more complex. Host names change, IP addresses change, NIC changes, hard drives change, operating systems are reinstalled or upgraded, and so on. In most of these cases, the assets are not necessarily considered “new”.
Within ServiceNow DataFlow, the initial step involves comparing the source key of the source adapter with the target key of the target adapter. If the match is found, it is a primary key match for the record. This implies that the correlation between the records in ServiceNow and Bigfix will remain intact, irrespective of any subsequent checks on the identity properties. If the match is not found the process proceeds to use the weighted confidence algorithm for machine correlation matching.
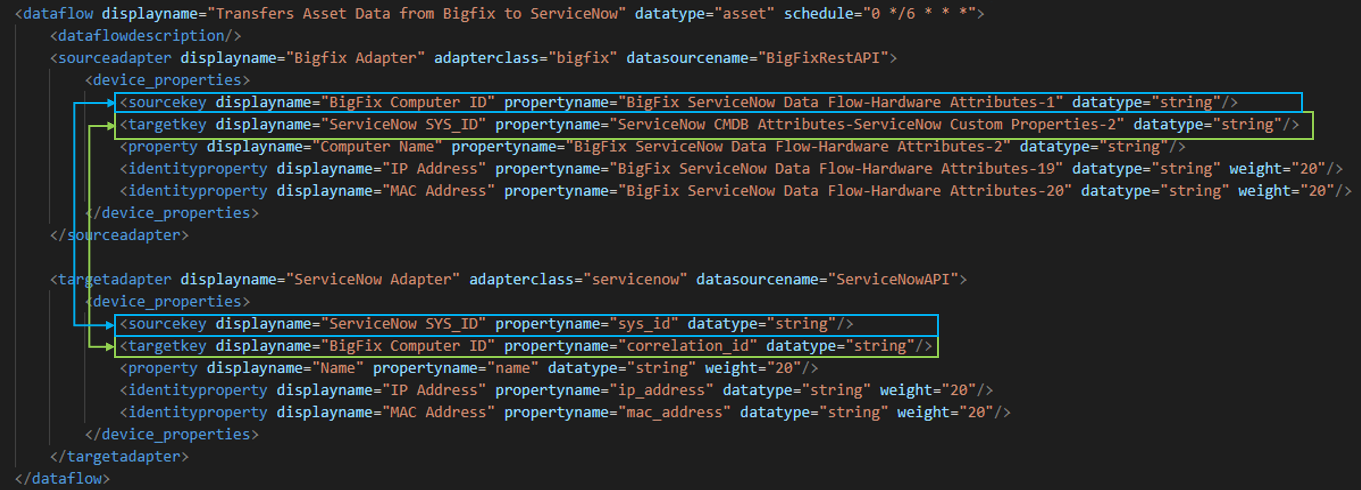
A weighted confidence algorithm that is configured within the data flow performs this initial mapping. Each data flow is configured with the MinimumConfidenceLevel property which is in global setting, which defines the weight of combined matches that are acceptable for assuming a match. If the combined weight of matching properties exceeds this threshold, then the record is considered a match and the key is mapped to improve performance of the subsequent updates. This provides a lot of flexibility to adapt to the natural changes in an environment.
For ex: Lets assume the dataflow is from Bigfix to ServiceNow. In the first dataflow execution all the data from Bigfix gets loaded to ServiceNow. In the subsequent executions the machine correlation plays important role. Lets assume that the minimumconfidence level is set to 60 and below machine details are present in both Bigfix and ServiceNow. In the next execution the ip address from Bigfix is compared with ServiceNow.
| Machine | IP Address(weight = 30) | MAC Address(weight = 30) | Hostname(weight =30) |
|---|---|---|---|
| 1 | 19.45.67.2 | 2345.567.222 | Machine1 |
As the ip address matches, the confidence level is now 30 ( weight of ip address) . Next the system compares the mac address in Bigfix and ServiceNow and it matches so the confidence level is 60( weight of ip address + weight of mac address). Now as the confidence level is 60 which is equal to the miniumconfidencelevel, the record is either updated or kept in ServiceNow.
In the below example the mac address and hostname of the machine is changed but ip address remains as is. Now following the same steps as mentioned , the minimumconfidencelevel will not be reached and the system assumes it to be a new record and inserts it into ServiceNow.
| Machine | IP Address(weight = 30) | MAC Address(weight = 30) | Hostname(weight =30) |
|---|---|---|---|
| 1 | 19.45.67.2 | 2345.567.2234 | Machine2 |
Advanced Configurations
Data Flows
With BigFix ServiceNow Data Flow, administrators can uniquely design data flows to optimize performance and accuracy of machine correlation. The default configuration provides data flows to separate the synchronization of data for laptops, servers, and virtual machines. An administrator can synchronize a data flow on any number of different configuration properties, such as location, subnet, device type, operating system and so on.
Property Transformations
You can manipulate the value of a property by using property transformations. This could be useful in several scenarios requiring calculated fields such as maintenance windows or enumerations. Property transformations are implemented in Python language.<property displayname= "Sample Property"
sourcecolumnname= "SampleProp"
datatype= "Integer">
<transformationlogic>
<![CDATA[this_value+1]]>
</transformationlogic>
</property>Filter Queries
<sourceadapter displayname = "My first source adapter"
adapterclass = "bigfixrest"
datasourcename = "MyDataSource">
<filterquery>
<![CDATA[
relay hostname of it is "Relay1"
]]>
</filterquery>
<properties></properties>
</sourceadapter>
Preview Data
The BigFix ServiceNow Data Flow can be configured to export changes instead of updating the target system. This feature enables administrators to test Data Flow configurations without the solution updating the target system. To enable this functionality, the PreviewOnly setting in the configuration file should be set to True. While this setting is enabled, the Target Adapter writes any planned changes in to a CSV file in the installation path, where the installation path is C:\Program Files (x86)\BigFix Enterprise\Dataflow.
Naming convention of CSV files:
- ServiceNow Dataflow from Bigfix To ServiceNow:
Preview-[0]-[servicernow]-YYYYMMDDHHMMSS.csv.
Ex.: Preview-[0]-[servicernow]-20220511140308.csv
- ServiceNow Dataflow from ServiceNow to Bigfix:
Preview-[1]-[bigfix]-YYYYMMDDHHMMSS.csv
Ex.: Preview-[1]-[bigfix]-202205118004051.csv
Update Throttling
With Update Throttling, adminstrators can tune the performance of the service so as not to negatively impact the target data source. This can be enabled and tweaked with the following two settings for each adapter in the configuration file: QueueRefreshInterval and UpdateBatchSize.
The QueueRefreshInterval determines the frequency that a given adapter looks for changes to be sent to the target data source. It is set to 120 seconds or about 30 potential updates per hour by default. The UpdateBatchSize determines the number of records that can be processed in a single update and its default value is 0.
In a scenario where QueueRefreshInterval is set to 120 seconds and UpdateBatchSize is set to 50, the solution would be throttled to 1500 updates per hour or 36,000 updates per day.