Contacting the remote engine in a failover scenario
- Define a distributed remote engine workstation for the master domain manager and for each backup master domain manager.
- Define each remote engine workstation as the alternate workstation for the previous one.
RENG that
points to the master domain manager MDM on the distributed HCL Workload Automation.
You have also defined the remote engine workstations REW1 and REW2,
respectively pointing to the backup master domain managers BMDM1 and BMDM2.
If the master domain manager is switched to a backup master domain
manager, to prevent the bind process from failing, define REW1 as
the alternative workstation for RENG, and REW2 as
the alternative workstation for REW1. 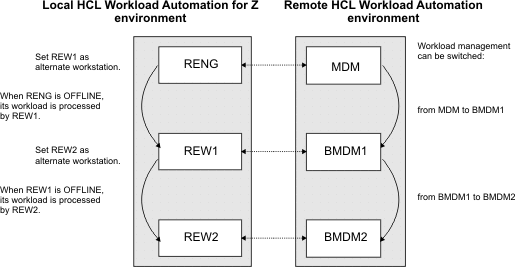
If all the primary and alternate remote engine workstations are OFFLINE, the requests are queued and will be managed by the first of these workstations that will become ACTIVE again. If more than one of these workstations becomes ACTIVE simultaneously, the requests will be managed by the highest remote engine workstation in the cascade.
When the remote engine is a Z controller the failover scenario is managed automatically by the SYSPLEX so you do not need to define any alternate remote engine workstation. In fact, a single HTTP address is sufficient to manage in a transparent way failover scenarios because the configuration with a hot standby controller is supported through Dynamic Virtual Internet Protocol Addressing - VIPA and controller and standby controller listen on the same hostname and port.