Configuring fixed width files as a data source
Fixed width files contain columns of data that are in fixed positions within the file (for example, "Emp/Last Name" uses the first 15 characters, "Emp/First Name" uses the next 15 characters).
About this task
Procedure
- Click Browse to select
the data source file and select the Fixed Width option.
If the test data source location is on a mapped network drive, you might get errors when running tests. To prevent any errors, ensure that the files are available on a local drive that can be accessed by HCL OneTest™ API.
- Indicate how you are going to define the
data field locations in the source file:
- Offset/Width: "offset" equals the number of characters that precede the field and "width" equals the number of characters that are used by the field.
- Start Char/End Char: "start char" is the position directly before the field starts and "end char" is the last position of the field. "Start char" for the first field is always zero, which is one less than the first position in the file (that is, one). "End char" for all fields equals the length of the field plus its starting value, and this value is carried to "Start char" for the next field.
- Click Import to set
the rules for determining the data locations. The Import
Config dialog is displayed.
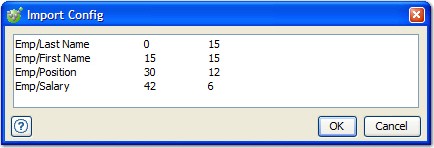
- Enter the rules or paste rules that were
previously copied to the clipboard. Rules must be entered in the following
format: Field Name<tab>value<tab>value
As an example, take the following file content:
Thompson Aaron Developer 72000 Miller James Developer 68000 Bryant Samuel Tester 54000 Jones Richard Tester 56500In this file, "Emp/Last Name" uses the first 15 characters, "Emp/First Name" uses the next 15 characters, "Emp/Position" uses the next 12 characters, and "Emp/Salary" uses the last six characters. The fields are "padded" with spaces.
The corresponding rules for this file are shown:
Offset/Width Rules Start Char/End Char Rules Emp/Last Name 0 15 Emp/Last Name 0 15 Emp/First Name 15 30 Emp/First Name 15 30 Emp/Position 30 42 Emp/Position 30 42 Emp/Salary 42 48 Emp/Salary 42 48Note: Start Char/End Char rules are converted to Offset/Width figures when displayed in the data source configuration dialog. - If the fields in your files are padded with extra characters so that they fill their space in the line, select the Trim cell padding option and specify the padding character. This character is removed when data is extracted.
- If Auto map new columns to tags at runtime is selected (the default value), then the values in any new columns that are added to the test data set are used as test data. This assumes that a tag exists that exactly matches each new column name and that the column count property is not set.
- If the number of test iterations can exceed the number of rows in the file, enable the Loop Data option to force HCL OneTest™ API to process the same rows over and over.
- Click Refresh to generate a preview of the data that are returned.
- Save the data source when finished, then see Creating tags from data source fields for details about copying column names to create tags from them.