Example of a complex failover recovery strategy
This topic describes a three-tiered server approach for achieving maximum availability in the case of a large region-wide disaster.
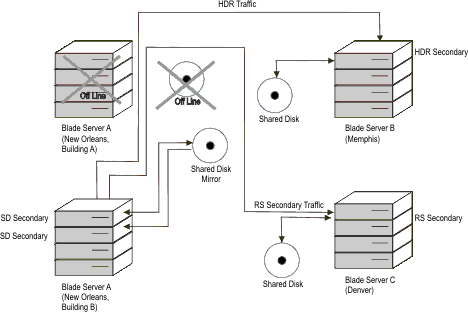
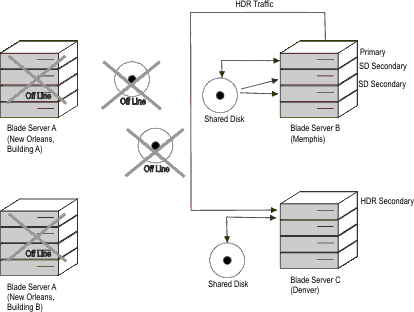
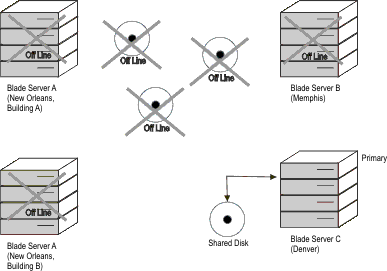
In general, an HDR Secondary server provides backup for SD secondary servers and provides support for a highly available system which is geographically remote from the main system. RS secondary servers provide additional availability for the HDR secondary and are viewed as a disaster-availability solution. If you must use an RS secondary server for availability, then you are forced to manually rebuild the other systems by performing backup and restore in order to return to normal operation. To further understand this, a scenario is presented in which a large region-wide disaster occurs, such as a hurricane.
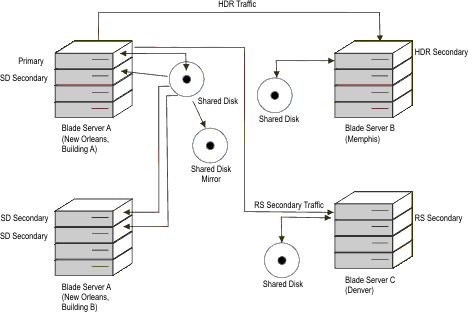
To provide maximum availability to survive a regional disaster requires layered availability. The first layer provides availability solutions to deal with transitory local failures. For example, this might include having a couple of blade servers attached to a single disk subsystem running SD secondary servers. Placing the SD secondary servers in several locations throughout your campus makes it possible to provide seamless failover in the event of a local outage.
You might want to add a second layer to increase availability by including an alternative location with its own copy of the disks. To protect against a large regional disaster, you might consider configuring an HDR secondary server located some distance away, perhaps hundreds of miles. You might also want to make the remote system a blade server or some other multiple-server system. By providing this second layer, if a fail-over occurs and the remote HDR secondary became the primary, then it would be possible to easily start SD secondary servers at the remote site.
However, even a two-tiered approach might not be enough. A hurricane in one region can create tornadoes hundreds of miles away. To protect against this, consider adding a third tier of protection, such as an RS secondary server located one or more thousand miles away. This three-tier approach provides for additional redundancy that can significantly reduce the risk of an outage.
| Requirement | Suggested configuration |
|---|---|
| You periodically must increase reporting capacity | Use SD secondary servers |
| You are using SAN devices, which provide ample disk hardware availability, but are concerned about server failures | Use SD secondary servers |
| You are using SAN devices, which provide ample disk hardware mirroring, but also want a second set of servers that are able to be brought online if the main operation is lost (and the limitations of mirrored disks are not a problem) | Consider using two blade centers running SD secondary servers at the two sites |
| You want to have a backup site some moderate distance away, but cannot tolerate any loss of data during failover | Consider using two blade centers with SD secondary servers on the main blade center and an HDR secondary on the remote. |
| You want to have a highly available system in which no transaction is ever lost, but must also have a remote system on the other side of the world | Consider using a local HDR secondary server that is running fully synchronous mode or nearly synchronous mode for data replication, and also using an RS secondary server on the other side of the world. |
| You want to have a high availability solution, but because of the networks in your region, the best response time from a ping is about 200 ms | Consider using an RS secondary server |
| You want a backup site but you do not have any direct communication with the backup site | Consider using Continuous Log Restore with backup and recovery |
| You can tolerate a delay in the delivery of data as long as the data arrives eventually; however you must have quick failover in any case | Consider using SD secondary servers with hardware disk mirroring in conjunction with ER. |
| You require additional write processing power, can tolerate some delay in the delivery of those writes, require something highly available, and can partition the workload | Consider using ER with SD secondary servers |