Tutorial: Elasticsearch file ingestion
Ingest unstructured data for MS Word .docx, PDFs, Excel.xlsx, CSV files, .txt files, and HTML files, including media metadata.
About this task
Procedure
-
In the Elasticsearch container, enable the support (plugin) attachment
docker.elastic.co/elasticsearch/elasticsearch:7.x.0.
- From the terminal window execute the following
command:
docker exec -it -u 0 commerce_elasticsearch_1 bash - From the container bash terminal, run the following
command:
elasticsearch-plugin install ingest-attachment - Restart the elasticsearch docker:
docker restart commerce_elasticsearch_1 - After adding the attachment command to the dockerfile, create a new Elasticsearch image from the base image.
- From the terminal window execute the following
command:
-
Create the commerce/search-nifi-app:9.1.x.0. directory in
the NiFi container using the following comands:
-docker exec -it -u 0 commerce_nifi_1 bash -mkdir /opt/nifi/extDocs/ chown nifi:nifi /opt/nifi/extDocsTo copy the files to the directory you wish to ingest into Elasticsearch, execute the following command on the command line:
In this example the following files will be used: SampleDocs-travel-laptop.docx and SampleDocs-office-laptop.ppt.docker cp /home/ingestfiles/. commerce_nifi_1:/opt/nifi/extDocs/. -
Import the following connectors into the NiFi registry
commerce/search-registry-app:9.1.x.0.
- docker cp
custom-UnstructuredIndexSchemaUpdateConnector-attachment.json
commerce_registry_1:/opt/nifi-registry/flows/.
For more information see, custom-UnstructuredIndexSchemaUpdateConnector-attachment.json.
- docker cp custom-UnstructuredIndexSchemaUpdate.json
commerce_registry_1:/opt/nifi-registry/flows/.
For more information see, custom-UnstructuredIndexSchemaUpdate.json.
- docker cp
custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.json
commerce_registry_1:/opt/nifi-registry/flows/.
For more information see, custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.json.
Open the NiFi registry container and run the following command:docker exec -it -u 0 commerce_registry_1 bashRun the following commands from the registry terminal.- /opt/nifi-registry/scripts/import_flow.sh custom-UnstructuredIndexSchemaUpdateConnector-attachment /opt/nifi-registry/flows/custom-UnstructuredIndexSchemaUpdateConnector-attachment.json
- /opt/nifi-registry/scripts/import_flow.sh custom-UnstructuredIndexSchemaUpdate /opt/nifi-registry/flows/custom-UnstructuredIndexSchemaUpdate.json
- /opt/nifi-registry/scripts/import_flow.sh custom-UnstructuredIndexDatabaseConnectorPipe-Attachment /opt/nifi-registry/flows/custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.json
- docker cp
custom-UnstructuredIndexSchemaUpdateConnector-attachment.json
commerce_registry_1:/opt/nifi-registry/flows/.
-
Using the Postman, create a ingest connector. For more
information, see Swagger UI.
Open the Postman and enter the following details:
- URL - http://localhost:30800/connectors
- Method = POST
- Body = the following json body:
{ "name": "auth.unstructured", "description": "This is the connector for the unstructured processing", "pipes": [ { "name": "custom-UnstructuredIndexSchemaUpdate" }, { "name": "custom-UnstructuredIndexSchemaUpdateConnector-attachment" }, { "name": "custom-UnstructuredIndexDatabaseConnectorPipe-Attachment", "properties": [ { "name": "Database Driver Location(s)", "value": "${AUTH_JDBC_DRIVER_LOCATION}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Database Connection URL", "value": "${AUTH_JDBC_URL}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Database User", "value": "${AUTH_JDBC_USER_NAME}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Password", "value": "${AUTH_JDBC_USER_PASSWORD}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } } ] }, { "name": "Terminal" } ] }
-
Add the process group to the NiFi UI and link the input/ output ports as shown
in the image below. Four process group pipes will be available in NiFi after you
run the connector:

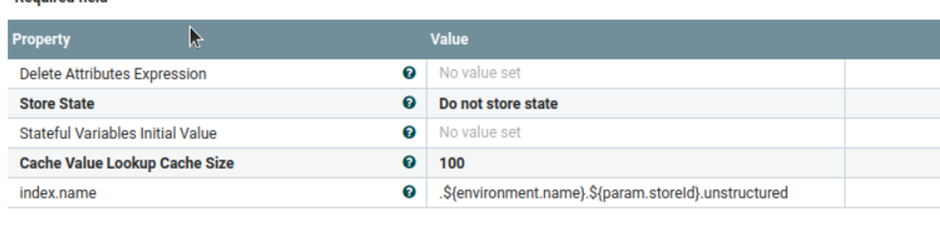
- a) custom-UnstructuredIndexSchemaUpdate
- This process group is used by Elasticsearch to enable attachment
settings. If the attachment setting is already enabled, it will be
skipped. Change the index name in the
schema name properties file to utilise an existing schema.
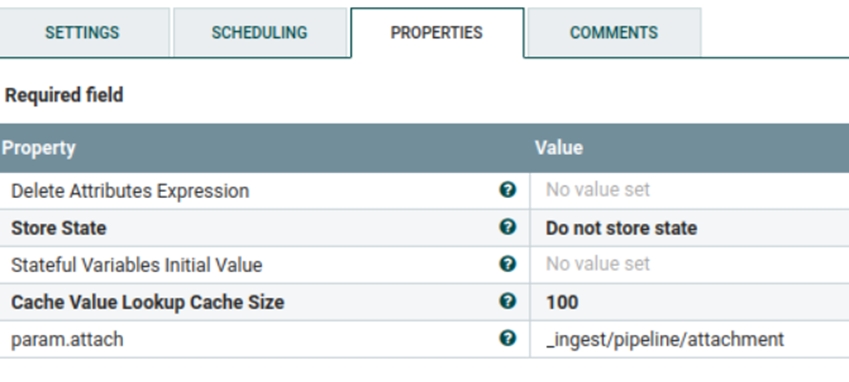
- b) custom-UnstructuredIndexSchemaUpdateConnector-attachment
- This process group is used by Elasticsearch to enable attachment
settings. If the attachment settings are already accessible, it will
be skipped. The following settings are used by default, but you can
update them to match your requirements. In the Set
unstructured attachment' processor,
param.attach is accessible.
 The following json code is available in the Populate unstructured Index schema processor. Here you can add or update a keyword. This keyword will be used for ingesting and searching unstructured data.
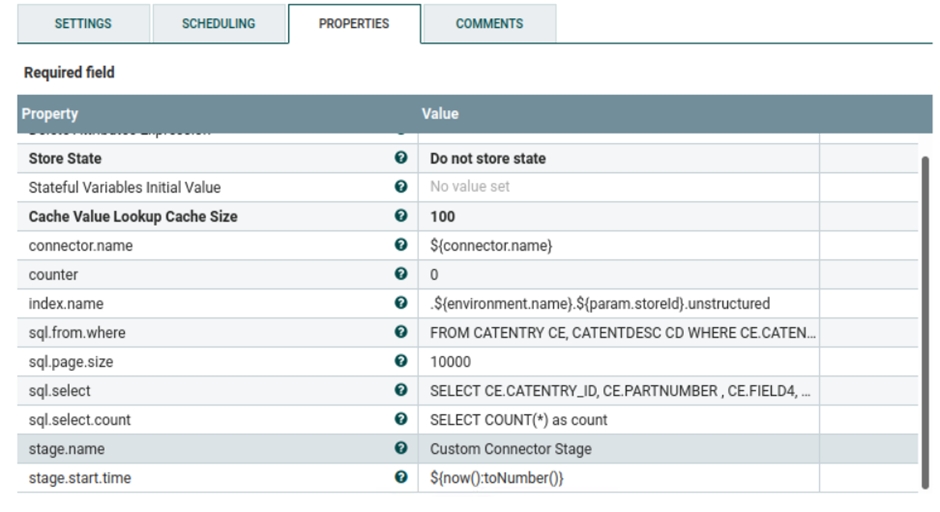
The following json code is available in the Populate unstructured Index schema processor. Here you can add or update a keyword. This keyword will be used for ingesting and searching unstructured data.{ "description" : "Extract attachment information", "processors" : [ { "attachment" : { "field" : "data", "indexed_chars_field" : "max_size", "properties": [ "content", "title", "keywords", "content_type", "content_length" ] } } ] } - c) custom-UnstructuredIndexDatabaseConnectorPipe-Attachment
- This process group is responsible for fetching the file locations
from the database, reading file content from the database's
specified directory, encoding it into the
base64, and ingesting it into the
Elasticsearch. Multiple processors are used by this process group to
import files into the Elasticsearch.
The Set Attribute processor is used to specify the parameter that will be used to process the file, which you may change as needed.
- d) Terminal
- This process group completes the process flow and is responsible for terminating the previous process's output.
-
Run the following queries to set the file location in
Catentry.field4 (this table is currently being used in
the process group). You can modify the query and add multiple transactions as
needed to set the file location for catalog entries.
UPDATE catentry SET FIELD4 = '/opt/nifi/extDocs/SampleDocs-travel-laptop.docx' WHERE PARTNUMBER = 'CLA022_2203' UPDATE catentry SET FIELD4 = '/opt/nifi/extDocs/SampleDocs-office-laptop.ppt' WHERE PARTNUMBER = 'CLA022_2205'Note: If you want to set the file location in a different table, you will have to modify the following properties in the Set Attribute processor under custom-UnstructuredIndexDatabaseConnectorPipe-Attachment. Currently the queries below are being used. You can update or modify them as needed.
Currently the queries below are being used. You can update or modify them as needed.SELECT COUNT(*) as count FROM CATENTRY CE, CATENTDESC CD WHERE CE.CATENTRY_ID = CD.CATENTRY_ID AND CD.LANGUAGE_ID =-1 AND CE.MARKFORDELETE =0 AND CE.BUYABLE =1 AND CD.PUBLISHED =1 AND ce.FIELD4 IS not NULL AND CE.CATENTRY_ID IN (SELECT C.CATENTRY_ID FROM CATGPENREL R, CATENTRY C WHERE R.CATALOG_ID IN (SELECT CATALOG_ID FROM STORECAT WHERE STOREENT_ID IN (SELECT RELATEDSTORE_ID FROM STOREREL WHERE STATE = 1 AND STRELTYP_ID = -4 AND STORE_ID = ${param.storeId})) AND R.CATENTRY_ID = C.CATENTRY_ID AND C.MARKFORDELETE = 0 AND C.CATENTTYPE_ID <> 'ItemBean') SELECT CE.CATENTRY_ID, CE.PARTNUMBER , CE.FIELD4, CD.NAME, CD.SHORTDESCRIPTION , CD.PUBLISHED FROM CATENTRY CE, CATENTDESC CD WHERE CE.CATENTRY_ID = CD.CATENTRY_ID AND CD.LANGUAGE_ID =-1 AND CE.MARKFORDELETE =0 AND CE.BUYABLE =1 AND CD.PUBLISHED =1 AND ce.FIELD4 IS not NULL AND CE.CATENTRY_ID IN (SELECT C.CATENTRY_ID FROM CATGPENREL R, CATENTRY C WHERE R.CATALOG_ID IN (SELECT CATALOG_ID FROM STORECAT WHERE STOREENT_ID IN (SELECT RELATEDSTORE_ID FROM STOREREL WHERE STATE = 1 AND STRELTYP_ID = -4 AND STORE_ID = ${param.storeId})) AND R.CATENTRY_ID = C.CATENTRY_ID AND C.MARKFORDELETE = 0 AND C.CATENTTYPE_ID <> 'ItemBean')Note: If you want to update the name of the schema where the file attachment will be ingested, modify the following properties in the Set Attribute processor under custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.
-
Connect the auth.unstructured -
custom-UnstructuredIndexSchemaUpdate process group with the
Routing Service process group with the INPUT set to
auth.unstructured.
Note: If the connection procedure is followed, this process should already be linked to the routing service. Ensure that the auth.unstructured route is working.
-
Navigate to the following process group.

- Select the Execute SQL processor.
- Right click and select View Configuration.
- Select the Arrow button at the right side of the
following property.

- Make sure the Database Connection pool service is enabled.

-
Start each of the four process groups, then go inside each one of them and
right-click on the NiFi flow and then select Enable
Transmission..
Note: It is possible that transmissions have already been activated.
-
After starting the process group run the following URL from
Postman.
POST- https://localhost:5443/wcs/resources/admin/index/dataImport/build?connectorId=auth.unstructured&storeId=1To check the status:GET- https://localhost:5443/wcs/resources/admin/index/dataImport/status?jobStatusId=1036 -
You may now validate indexed unstructured data and pass the keyword you
specified when setting up the attachment:
POST - localhost:30200/.auth.1.unstructured/_searchBody: With Content available in file.{ "query": { "bool": { "must": [ { "query_string": { "query": "lightweight" } } ] } } }Body – with SKU (partnumber).{ "query": { "bool": { "must": [ { "query_string": { "query": "CLA022_2205" } } ] } } }Body – with file extension.{ "query": { "bool": { "must": [ { "query_string": { "query": "docx" } } ] } } }