
Solr search sharding
Sharding overview
To distribute an index, you divide it into partitions called shards. Shards can share
the same Search Docker container or be run separately in their own Search
containers, depending on system performance. If your Search shard containers and the
Search master container are not located in the same virtual machine or physical
machine, you can require extra distributed file system technology, such as
remoteStorage, to allow the Search shard containers to share an
index folder with the master container.
Once all of the index shards are successfully populated, they can be merged in one optimized index, to be used with your storefront for sorting, faceting and filtering.
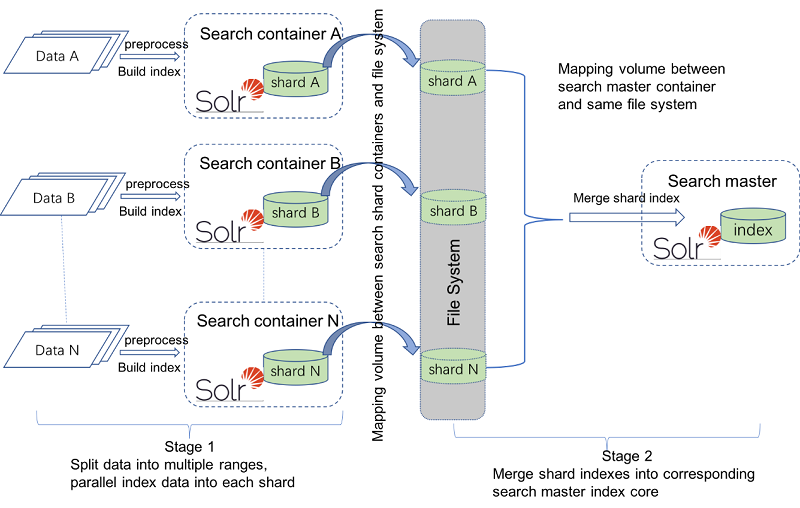
There are two stages to index sharding with multiple JVMs, as there are with a single JVM. In the first stage, the original data is split into multiple ranges. Each range of data is preprocessed and they are indexed into a shard’s index cores in parallel. In the second stage, all the shards’ index cores are merged into the Search master's corresponding index core. For example, CatalogEntry structured shard indexes are merged into the Search master CatalogEntry structured index, and unstructured shard indexes are merged into the Search master unstructured index core. For multiple JVMs, the standard approach is to build each shard index in a separate Search server container. If system resources permit, you can configure one Search server to build multiple shard indexes.
Some extra steps are needed to map volumes between containers and an outside file system. The Search master container needs this mapping so that it can access all shard index folders.
Once you have set up your shard environment, you can then perform indexing to each shard using the di-parallel-process utility. The following diagram shows the two stages for sharding in multiple search docker containers.
Sharding considerations
- Determine the number of shards that you will be using, based on the available capacity of your server. At least one CPU core must be available for each separate index shard.
- If you are using index replication, do not configure any of your index shards to participate in your index replication network. These shards are only used for index building. The final version of the index should be on the master server, which should then be replicated to the repeater and then to the subordinates.
- Allocate enough heap memory for each of your index shards. Refer to HCL Commerce Search performance tuning for recommendations on how to configure the solrconfig.xml configuration file.
Sharding deployment
Kubernetes and Docker Compose-based deployment guidelines and samples are provided with the release of HCL Commerce 9.1.16.0.