Pipeline d'index Synonyme Ingest
Mappage de la zone d'index Synonyme à partir de la spécification de données
Le diagramme suivant illustre le pipeline d'indexation Synonyme implémenté dans Apache NiFi. Le flux se compose principalement de trois étapes :
- Générer un document de dictionnaire Synonyme pour ElasticSearch basé sur le synonyme d'entrée par langue.
- (SI POST) Extraire les synonymes actuels dans le dictionnaire d'index de produit et les ajouter au document généré à l'étape 1.
- Mettre à jour les dictionnaires spécifiques à la langue du produit avec le document Synonyme généré lors des étapes 1 et 2.
- Initial
- APPEL PUT ou POST REST : http://<Hostname>:30700/connectors/JsonSynonym/data
{ "synonyms": { "english": { "synonyms": [ "coff => coffee", "driveway, road, street" ] }, "french": { "synonyms": [ "coff => coffee", "driveway, road, street" ] } } } - 1. Générer le document du dictionnaire Synonyme
- Le flux de données suivant décrit comment les données Synonyme spécifiques à la langue peuvent être transformées à l'aide du script Groovy CreateSynonymBodyPart1.
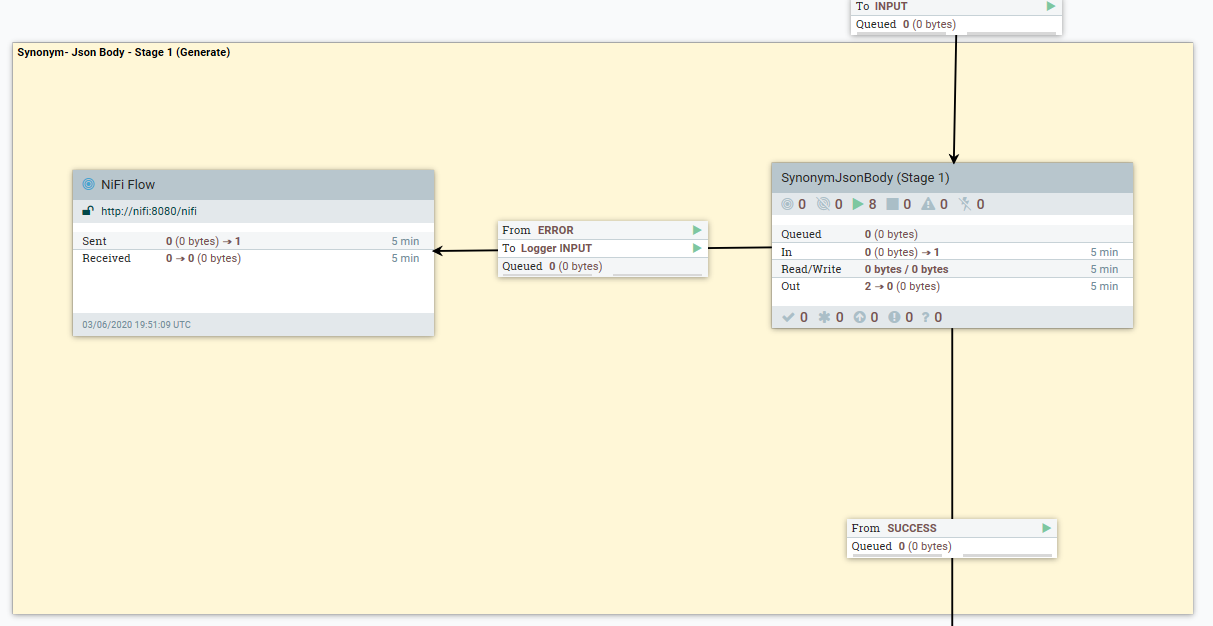
- 2. (SI POST) Extraire les synonymes actuels dans le dictionnaire d'index de produit et les ajouter au document généré
- Le flux de données suivant décrit ce qui se passe lorsque l'utilisateur effectue une requête POST* :
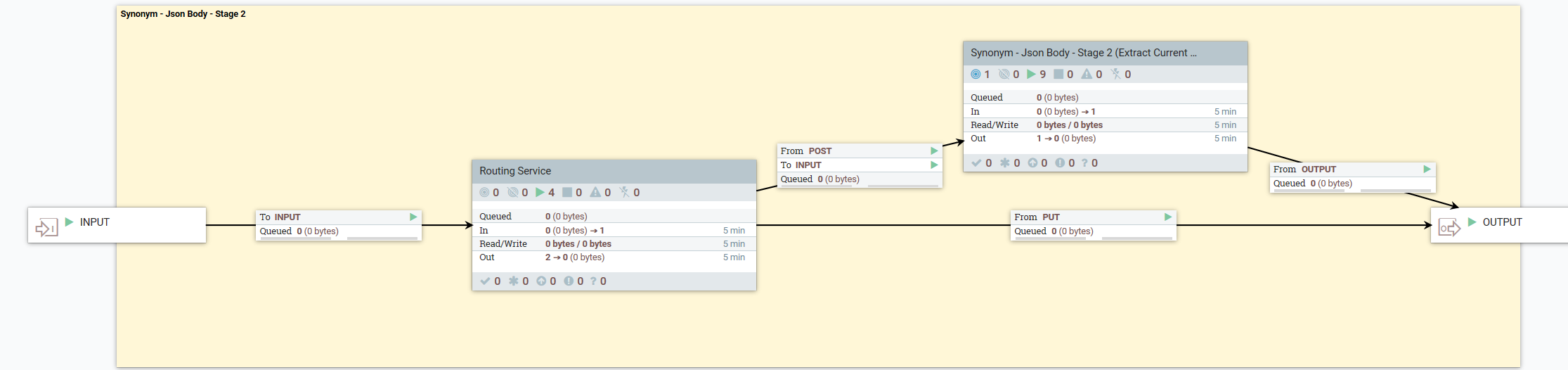
- 3. Mettre à jour les dictionnaires spécifiques à la langue du produit avec le document Synonyme
- Le flux de données ci-dessus décrit le processus de mise à jour (écrasement) du dictionnaire spécifique à la langue avec la documentation précédemment générée.

Mappage de la zone d'index Synonyme à partir de la base de données
Spécification des données :
Le diagramme suivant illustre le pipeline d'indexation Association des termes de recherche (STA) implémenté dans Apache NiFi. Le flux se compose principalement de deux étapes :
- Extraire les STA de base de données relatives à la valeur StoreID (et à la valeur storeID associée) et générer un document STA pour ElasticSearch.
- Mettre à jour les dictionnaires spécifiques à la langue du produit avec le document STA généré lors de l'étape 1.
- Etape 1 : Extraire les STA de base de données relatives à la valeur StoreID (et à la valeur storeID associée) et générer un document STA pour la ElasticSearch
- Le flux de données suivant décrit comment les données de la base de données STA peuvent être transformées à l'aide du script Groovy CreateSTABody.
.png)
- Etape 2. Mettre à jour les dictionnaires spécifiques à la langue du produit avec le document STA généré lors de l'étape 1.
- Le flux de données suivant décrit le processus
- Fermer l'index Produit
- Mettre à jour l'index Produit
- Ouvrir l'index Produit
.png)