Pipeline d'index Mot neutre Ingest
Les mots neutres sont facilement générés à l'aide du pipeline NiFi.
Mappage de la zone d'index Mot neutre à partir de la spécification de données
Le diagramme suivant illustre le pipeline d'indexation Mot neutre implémenté dans Apache NiFi. Le flux se compose principalement de trois étapes :
- Générer un document de dictionnaire Mot neutre pour ElasticSearch basé sur le mot neutre d'entrée par langue.
- (SI POST) Extraire les mots neutres actuels dans le dictionnaire d'index de produit et les ajouter au document généré à l'étape 1.
- Mettre à jour les dictionnaires spécifiques à la langue du produit avec le document Mot neutre généré lors des étapes 1 et 2.
- Initial
- APPEL PUT ou POST REST : http://<Hostname>:30700/connectors/JsonStopword/data
{ "stopwords": { "english": { "stopwords": ["step1", "car"] }, "french": { "stopwords": ["step2", "dark"] } } }
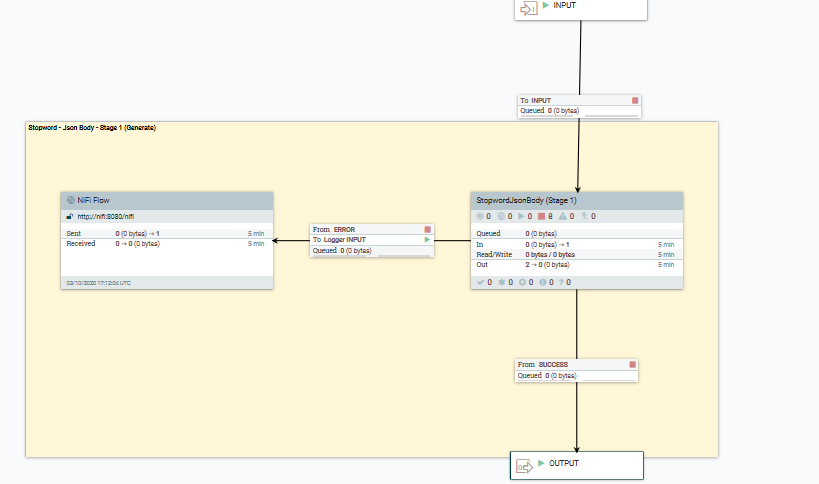
- Etape 1. Générer un document de dictionnaire Mot neutre
- Le flux de données suivant décrit comment les données Mot neutre spécifiques à la langue peuvent être transformées à l'aide du script Groovy CreateStopwordBodyPart1.
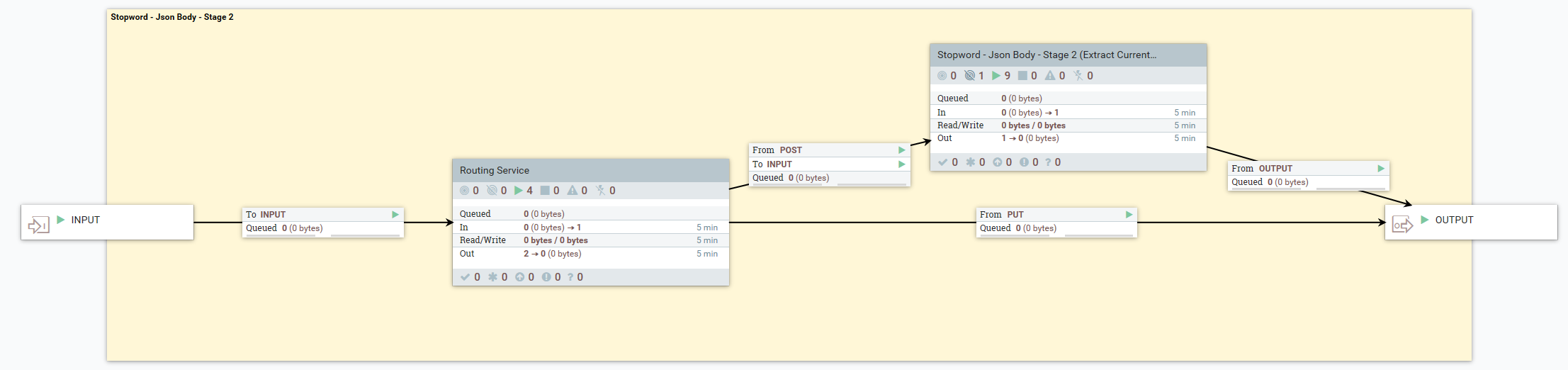
- Etape 2. (SI POST) Extraire les mots neutres actuels dans le dictionnaire d'index de produit et les ajouter au document généré
- Le flux de données suivant montre que, lorsque l'utilisateur fait une requête POST*, les étapes suivantes ont lieu :

- Etape 3. Mettre à jour les dictionnaires spécifiques à la langue du produit avec le document Mot neutre généré.
- Le flux de données suivant décrit le processus de mise à jour (écrasement) du dictionnaire spécifique à la langue avec la documentation précédemment générée lors des étapes suivantes :
- Fermer l'index Produit
- Mettre à jour l'index Produit
- Ouvrir l'index Produit
