
Tuning Index Load
You can tune Index Load for optimal performance by configuring the tunable values and evaluating the results.
Before you begin
About this task
Index Load starts with a single input source, uses multithreaded processing, and ends with a single batch service writing to a single index.
The following diagram shows the available tunable areas
of Index Load:
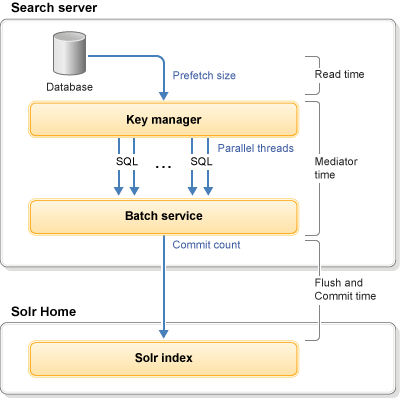
Where
the following main tunable areas exist:
- Parallel threads
- The number of threads to be used for parallel indexing.
- Prefetch size
- The number of rows to return for each database (SQL) call.
- Commit count (hard commit)
- The number of index documents to keep in memory before writing to the Solr index.
- Batch count (soft commit)
- The number of index documents to keep in the Index Load runtime
buffer before pushing them into the Solr memory stack.
The higher the batch count value, the higher the indexing throughput but with more garbage generated.
The following gauges of measurement exist to
determine performance, can be viewed from the Index Load status page:
- Rate
- The average number of documents indexed per second to the Solr stack.
- Read time
- The average amount of time spent running SQL calls.
- Flush time
- The average amount of time spent on Solr soft commits.
- Commit time
- The average amount of time spent on Solr hard commits.
- Indexing time
- The overall end-to-end time spent on indexing.
You can use these statistics to tune the main tunable areas of Index Load.
The following diagram shows how
Index Load works with chunks of data, and how you can tune the prefetch,
threads, and batch count for performance:
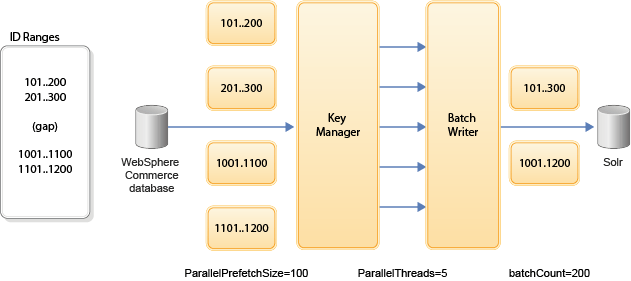
Where:
Where:
- The Key Manager uses Prefetch to get small chunks of data from the database and evenly distributes it across all worker threads. This technique avoids overloading the database when processing a very large of result set size. Very large result set sizes might not even fit into the database transaction log. By using smaller chunks of data, the query time is improved, and the Index Load thread workload is more evenly distributed.
- The prefetch size (ParallelPrefetchSize) defines the lookahead block size, whereas the next range SQL (ParallelNextRangeSQL) is used to address large empty ID range gaps. The next range SQL is only used when the lookahead contains no data. That is, when a gap is detected. This SQL is used to return the next available ID, and therefore avoids unnecessary crawling.
- The prefetch size, thread count, ranges, and batch count are all factors to consider when tuning Index Load.