Processing and monitoring critical jobs
Workload service assurance provides automatic tracking and prioritizing of critical network jobs and online functions that you use to monitor and intervene in the processing of critical network jobs.
Automatic tracking and prioritizing
- Promotion
- When the critical start time of a job is approaching and the job
has not started, the promotion mechanism is used. A promoted job is
assigned additional operating system resources and its submission
is prioritized.
The timing of promotions is controlled by the global option
promotionoffset. Promoted jobs are selected for submission after jobs that have priorities of "high" and "go", but before all other jobs. Prioritizing of operating system resources is controlled by the local optionsjm promoted nice(UNIX and Linux) andjm promoted priority(Windows). - Calculation of the critical path
- The critical path is the chain of dependencies, leading to the
critical job, that is most at risk of causing the deadline to be missed
at any given time. The critical path is calculated using the estimated
end times of the critical job predecessors. Working back from the
critical job, the path is constructed by selecting the predecessor
with the latest estimated end time. If the actual end time differs
substantially from the estimated end time, the critical path is automatically
recalculated. Critical path shows the critical path through a critical network at a specific moment during the processing of the plan.
Figure 1. Critical path 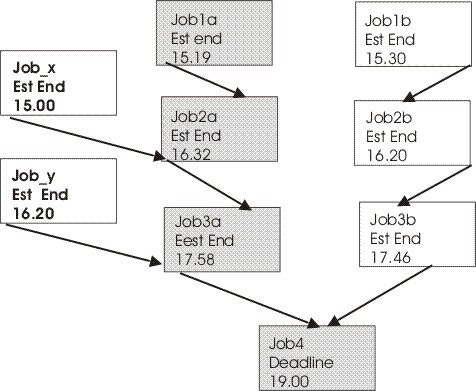
At this time, the critical path includes Job3a, Job2a, and Job1a. Job3a and Job3b are the immediate predecessors of the critical job, Job4, and Job3a has the later estimated end date. Job3a has two immediate predecessors, Job2a and Job_y. Job2a has the later estimated end time, and so on.
- Addition of jobs to the hot list
- Jobs that are part of the critical network are added to a hot
list that is associated to the critical job itself. The hot list includes
any critical network jobs that have a real or potential impact on
the timely completion of the critical job. Jobs are added to the hot
list for the one or more of the reasons listed next. Note that only
the jobs beginning the current critical network, for which there is
no predecessor, can be included in the hot list.
- The job has stopped with an error. The length of time before the
critical start time is determined by the
approachingLateOffsetglobal option. - The job has been running longer than estimated by a factor defined
in the
longDurationThresholdglobal option. - The job has still not started, though all its follows dependencies
have either been resolved or released, and at least one of the following
conditions is true:
- The critical start time has nearly been reached.
- The job is scheduled to run on a workstation where the limit is set to zero.
- The job belongs to a job stream for which the limit is set to zero.
- The job or its job stream has been suppressed.
- The job or its job stream currently has a priority that is lower than the fence or is set to zero.
- The job has stopped with an error. The length of time before the
critical start time is determined by the
- Setting a high or potential risk status for the critical job
- A risk status can be set for the critical job, as follows:
- High risk
- Calculated timings show that the critical job will finish after its deadline.
- Potential risk
- Critical predecessor jobs have been added to the hot list.
Online tracking of critical jobs
The Dynamic Workload Console provides specialized views for tracking the progress of critical jobs and their predecessors. You can access the views from the Dashboard or create a task to monitor critical tasks using Monitor Workload.
- The hot list of jobs that put the critical deadline at risk.
- The critical path.
- Details of all critical predecessors.
- Details of completed critical predecessors.
- Job logs of jobs that have already run.
- The confidence factor expressed as a percentage. The probability with which a critical job will meet its deadline.
Using the views, you can monitor the progress of the critical network, find out about current and potential problems, release dependencies, and rerun jobs.