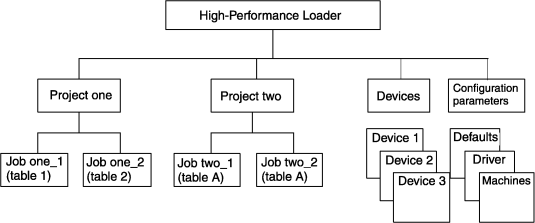
Project organization
The uses only one database, onpload, to track the preparation that you do for loading and unloading data. By using projects, you can organize your work into functional areas.
For example, you might regularly transfer data to or from several unrelated databases. You could put all of the preparation for each database into a separate project.
When you first start ipload, ipload creates a project named <default>. If you prefer, you can select the <default> project and assign all of your work to that project. The HPL does not require that you create any additional projects. However, creating projects and putting separate tasks into distinct projects makes your work easier to maintain.
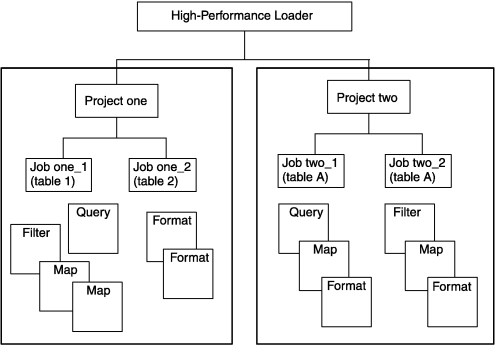
The preceding figure shows that jobs are linked directly to the projects. The format, map, filter, and query components belong to a project but are not directly linked to a job, as illustrated with Project One. In general, you create a format, map, and filter or query for each job, as shown with Project Two. However, in some cases, you might use the same component for more than one job within a project.
For example, for reports about a medical study, you might want to create three reports: one about subjects under 50 years of age, one about subjects over 50, and one about all subjects. In that case, the description of how to find the information (the format and map) is the same for all three reports, but the selection of information (the query) is different for each report. (Formats, maps, and queries are described in detail in later chapters.)
All components (maps, formats, queries, filters, and load and unload jobs) that you create in a project are associated with that project in the onpload database. Components that are associated with a project are visible (usable) only when the project is selected. When you select a different project, a different set of components becomes available.