Ingest Synonym index pipeline
Synonym index field mapping from data specification
The following diagram illustrates the Synonym indexing pipeline implemented in Apache
NiFi. The flow consists of mainly three stages:
- Generate Synonym dictionary document for Elasticsearch based on the input synonym per language.
- (IF POST) Extracting current synonyms in the product index dictionary, and adding them to the generated document from stage one.
- Update Product's language specific dictionaries with the synonyms document generated from Stage one and Stage two.
- Initial
- PUT or POST REST Call:
http://<Hostname>:30700/connectors/JsonSynonym/data
{ "synonyms": { "english": { "synonyms": [ "coff => coffee", "driveway, road, street" ] }, "french": { "synonyms": [ "coff => coffee", "driveway, road, street" ] } } } - 1. Generate Synonym Dictionary Documentt
- The following dataflow describes how the language specific Synonym data can be transformed using the CreateSynonymBodyPart1 Groovy script.
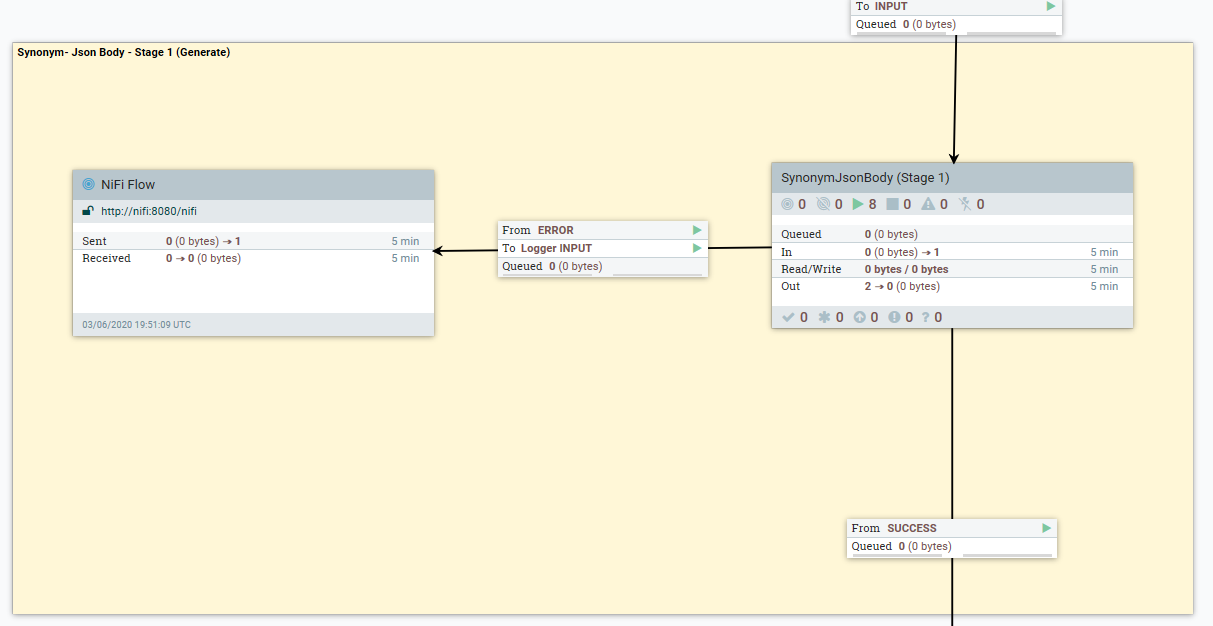
- 2. (IF POST) Extract current synonyms in the product index dictionary, and add them to the generated document
- The following dataflow decribes what happens when the user makes a POST* request:
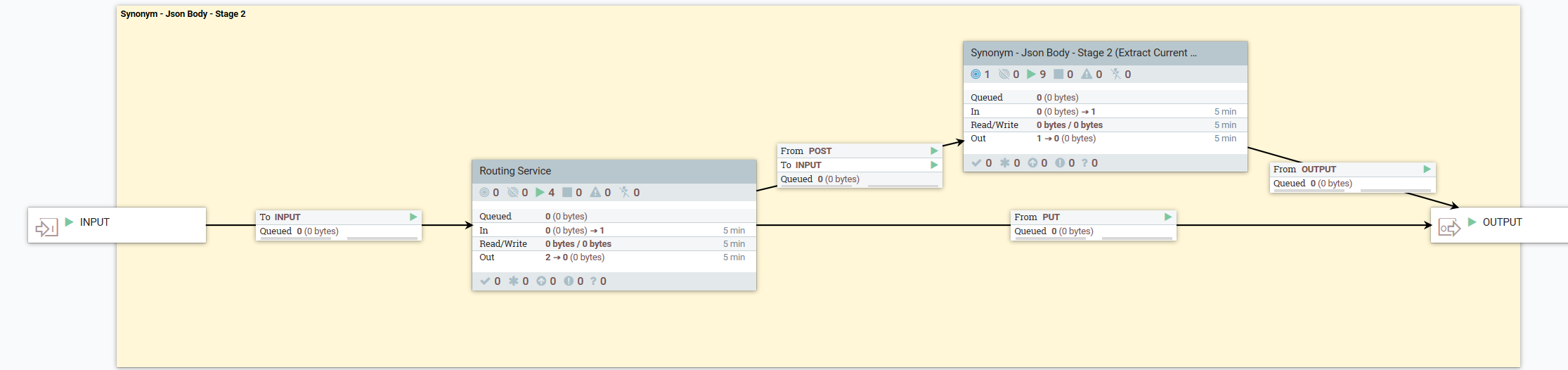
- 3. Update the Product's language specific dictionaries with the synonyms document
- The above dataflow decribes the process of updating (Overwriting) the Language Specific Dictionary with the previously generated documentation.

Synonym index field mapping from database
Data specification:
The following diagram illustrates the Search Term Assosication (STA) indexing
pipeline implemented in Apache NiFi. The flow consists of mainly two stages:
- Extract STAs from Database relative to StoreID (and related storeID) and Generate STA document for Elastic Search.
- Update Product's language specific dictionaries with the sta document generated from Stage One.
- Stage 1: Extract STAs from Database relative to StoreID (and related storeID) and Generate STA document for Elastic Search
- The following dataflow describes how the STA Database Data can be transformed using the CreateSTABody Groovy script.
.png)
- Stage 2. Update Product's language specific dictionaries with the STA document generated from Stage One
- The following dataflow decribes the proc
- Close Product Index
- Update Product Index
- Open Product Index
.png)