Cache invalidation using Kafka and ZooKeeper
You can use Apache Kafka and Apache ZooKeeper to do cache invalidation. Invalidation jobs can be run either from local or remote servers.
If you are not running Redis, you can use Kafka and ZooKeeper to run invalidation between Transaction servers, between a Transaction server and Store servers, or between a Transaction server and Search servers. If you are using Redis, Kafka is not required for cache invalidation. For more information, see HCL Cache with Redis.
 You can use Kafka to run invalidation between Transaction
servers, between a Transaction server and Store servers, or between a Transaction
server and Search servers. Zookeeper will only communicate with Kafka in this
circumstances. The general process flow for Kafka cache invalidation is shown
in the following diagram.
You can use Kafka to run invalidation between Transaction
servers, between a Transaction server and Store servers, or between a Transaction
server and Search servers. Zookeeper will only communicate with Kafka in this
circumstances. The general process flow for Kafka cache invalidation is shown
in the following diagram.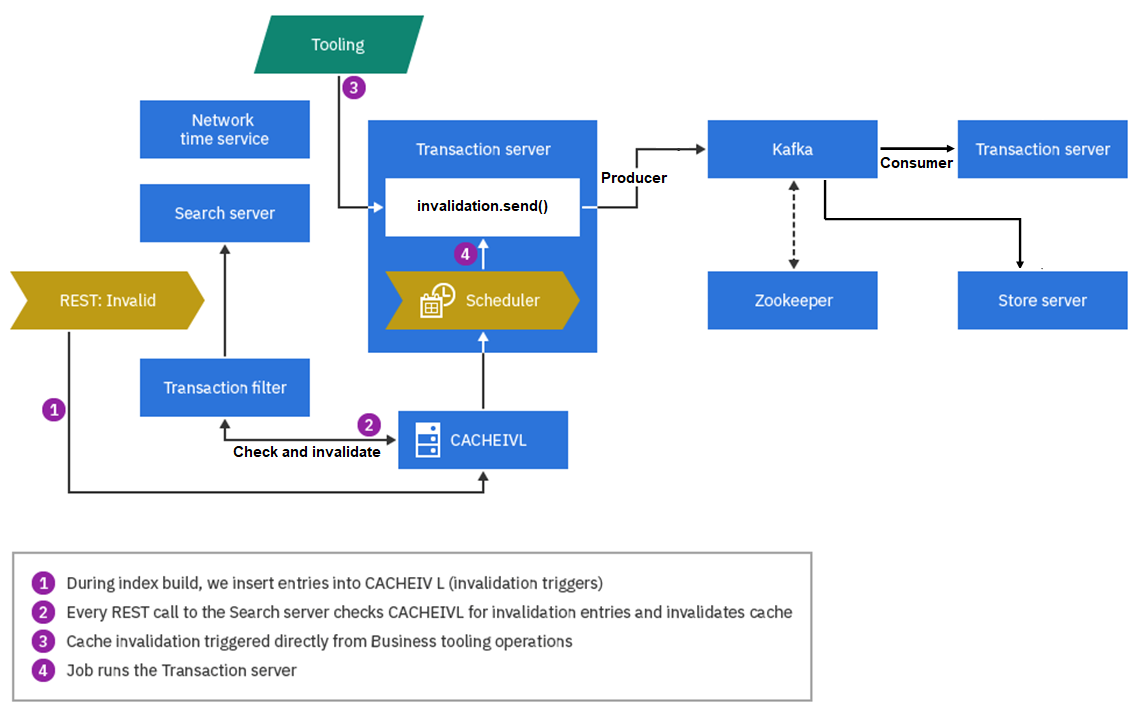
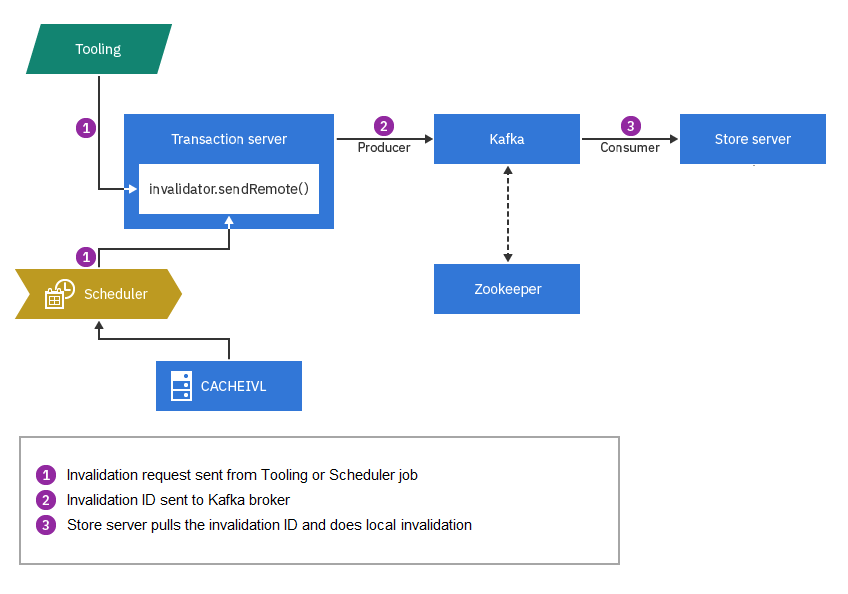
Invalidation between Transaction servers
topicnamePeerCacheInvalidation, where
topicname is your own Kafka topic name. The producer
sends messages to the Kafka broker, which appends them to the topic partitions.
For example, if a Business user is updating author data, her Transaction server
will send cache invalidation IDs to the Kafka broker when the invalidation
transaction is committed. The consumer Transaction server monitors the same
topics on the Kafka server, and when it detects message offset changes, it will
query the Kafka broker for the invalidation IDs. Then it will do the
invalidation using a pre-configured "DB table - Cache container" mapping.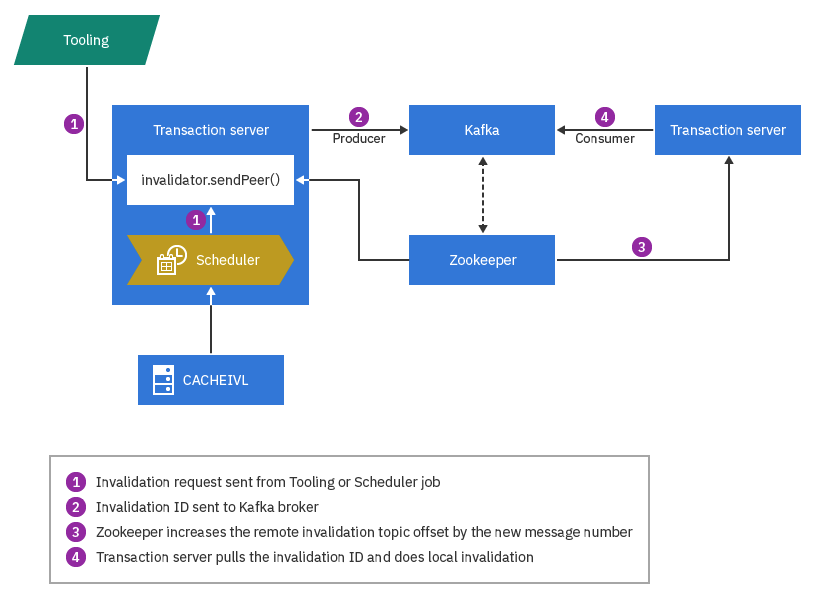
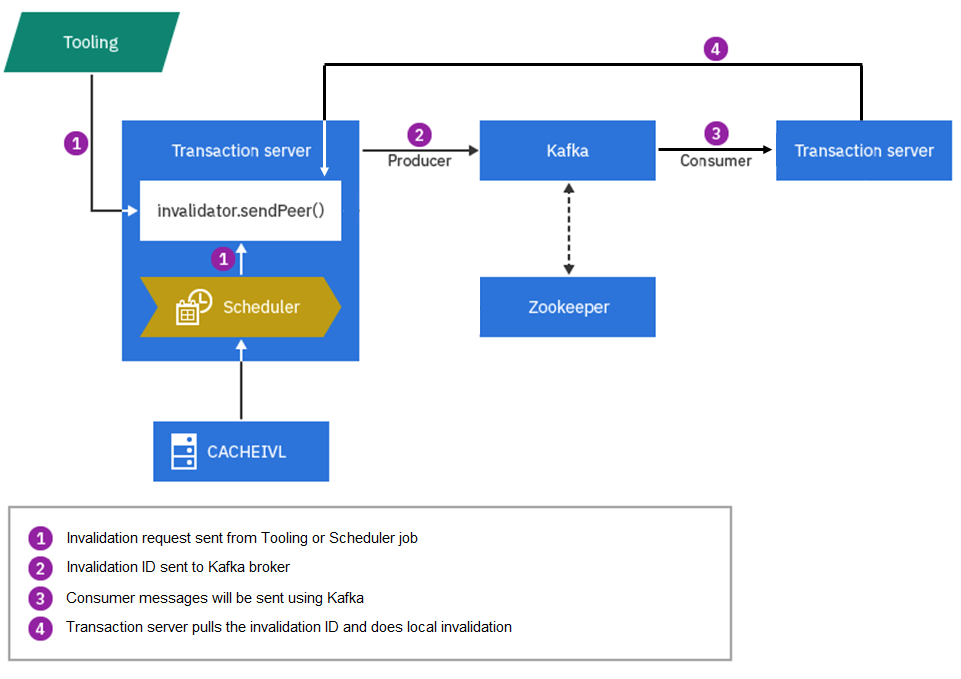
Some events, such as Data Load operations, do not directly trigger invalidation. Instead, database table triggers, index build jobs and other daily jobs place new records in the CACHEIVL table as they are run. The cache invalidation scheduler job scans the CACHEIVL table and picks up the latest changes. It will then perform local cache invalidation and send out invalidation messages to the Kafka broker. As in the previous example, when peer Transaction servers detect the new messages, it will do invalidation by pre-configured "DB table – Cache container" mapping.
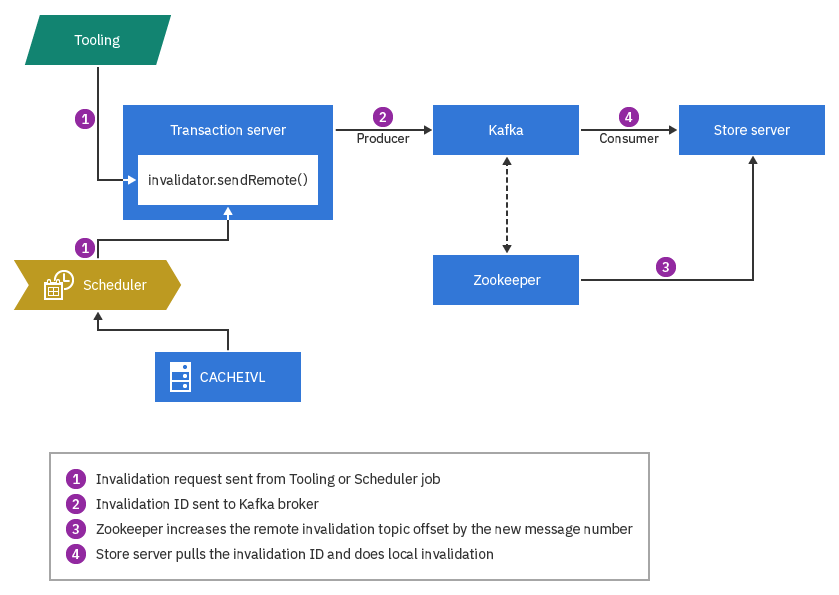
Invalidation between Transaction server and Store server
In this scenario, the Transaction server is the message producer and the remote
Store server is the message consumer. The cache invalidation topic in this
invalidation scenario is different from that of the Transaction-to-Transaction
invalidation scenario. If the same data needs to be invalidated on both Store
and and Transaction servers, the same invalidation ID will be appended to both
topics. The topic name for the Transaction-to-Store invalidation is structured
as topicnameCacheInvalidation.
Search server invalidation
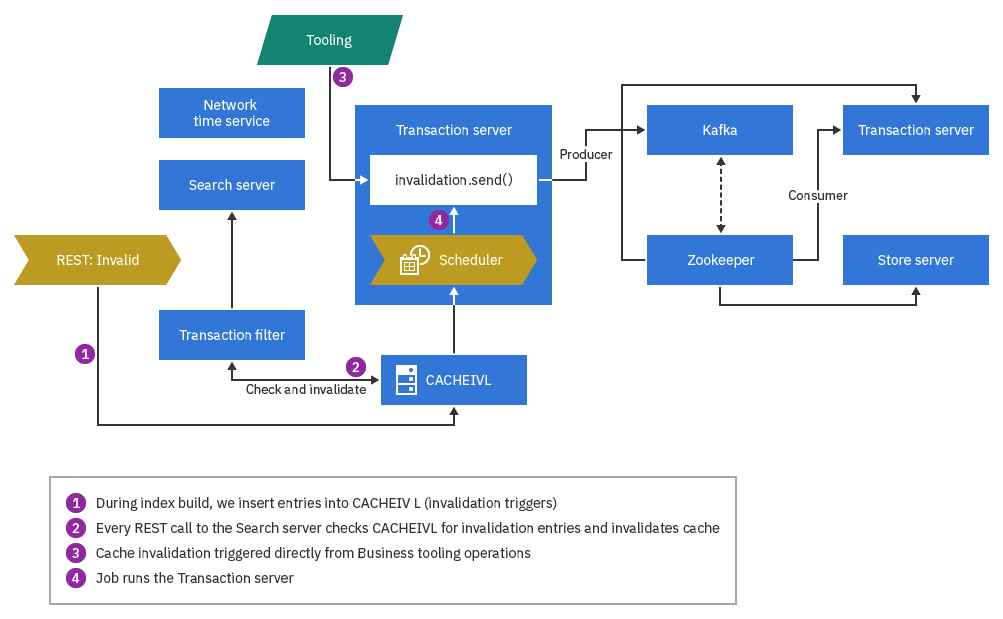
The Search server uses CACHEIVL to coordinate cache invalidation. All REST requests that are routed to the Search server go through a servlet filter named TransactionFilter. At preconfigured times, the filter checks for newly inserted CACHEIVL table records. These are selected for invalidation.
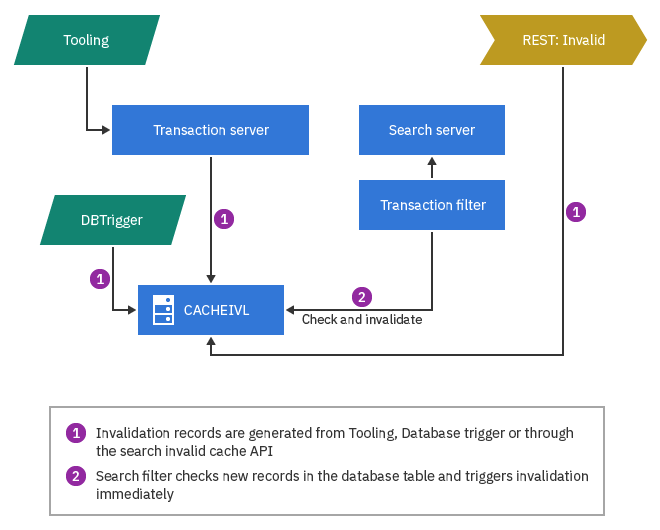
Customizable Cache invalidation after search index build
Cache invalidation on the Store server can use custom entries that were added by the Search server during the index build process. In this process, the Search server inserts the custom invalidation records into the CACHEIVL database table during the index build process. The database then sends the records to the Transaction server, which in turn makes invalidation requests to the Store server, where servlet cache invalidation is performed.
You can use the following setting to register the records in CACHEIVL when the invalidation REST API search/admin/resources/index/cache/invalidate is invoked.
<_config:property name="CacheInvalidationForCatalogEntry" value="productId:$catEntryId$,CategoryDisplay:storeId:categoryId:$storeId$:$catGroupId$" />
<_config:property name="CacheInvalidationForCatalogGroup" value="CategoryDisplay:storeId:categoryId:$storeId$:$catGroupId$" />
<_config:property name="CacheInvalidationForStoreHeader"value="StoreHeader:storeId:catalogId:$storeId$:$catalogId$,StoreHeader:storeId:$storeId$" />